
Płaskie protokoły rutingu
Protokoły fooding i gossiping.
Protokoły flooding i gossiping [6] były dwoma pierwszymi protokołami zaadoptowanymi na potrzeby sieci sensorowych. Działanie protokołu flooding jest bardzo proste i polega na tzw. „zalewaniu” czyli przekazywaniu każdej informacji do wszystkich swoich węzłów-sąsiadów. Z biegiem czasu okazało się, że protokół ma zbyt dużo wad i praktycznie nie nadaje się do stosowania w sieciach sensorowych. Głównymi wadami protokołu flooding jest powtarzanie informacji (ang. implosion) i pokrywanie się węzłów (ang. overlap) w przypadku gdy dwa węzły posiadają te same dane i rozpowszechniają je dalej. Dodatkowo, trzeba zauważyć, że protokół jest „ślepy” na zasoby posiadane przez węzeł co może powodować liczne uszkodzenia węzłów. Takie zachowanie protokołu skutkuje marnowaniem energii i pasma sieci co jest zagadnieniem kluczowym w sieciach sensorowych.
Chociaż protokół gossiping zapobiega powtarzaniu informacji poprzez losowy wybór węzłów (jednego lub grupy) do których ma być przekazywana informacja to takie rozwiązanie wprowadza opóźnienie propagacyjne. Flooding i gossiping nie były stworzone specjalnie dla sieci sensorowych i występujących w nich obostrzeń energetycznych przez co nie są wystarczająco efektywne energetycznie.
Protokół SPIN
Protokół SPIN (ang. Sensor Protocol for Information via Negotiation) to protokół sensorowy uzyskiwania informacji przez negocjację, który był pierwszym protokołem rutingu stworzonym specjalnie dla sieci sensorowych. Zalicza się on do protokołów inicjowanych źródłem, który używa płaskiej struktury sieci o rutingu reaktywnym (ang. source initiated, flat, reactive). Bazuje on na negocjacji między węzłami podczas rozpowszechniania informacji (ang. negotiation-based) i jest szczególnie przystosowanym do działania bezprzewodowych sieciach sensorowych. SPIN został stworzony na bazie konwencjonalnych protokołów rozpowszechniania informacji takich jak flooding poprzez analizę ich słabych i mocnych punktów. Jak już wcześniej wspomniano protokoły te mają liczne wady: powtarzanie informacji, pokrywanie się węzłów oraz brak analizy zasobów węzła. W związku z tymi negatywnymi cechami w protokole SPIN zostały zaimplementowane dwa mechanizmy, które pozwalają na ich przezwyciężenie. Pierwszy z nich to negocjowanie przed przystąpieniem do transmisji (ang. negotiation), co pozwala na przesyłanie tylko istotnych i potrzebnych informacji. Podczas negocjacji węzeł posiadający dane rozsyła informacje opisujące ich treść (ang. meta-data) i węzeł odbiorczy może wykazać chęć ich odbioru bądź nie. Drugim mechanizmem jest menadżer zasobów (ang. resource manager) zaimplementowany w każdy węzeł, który analizuje zasoby energetyczne węzła i w przypadku małej ilości energii ogranicza jego aktywność.
Podczas działania SPIN wykorzystuje trzy typy informacji do komunikacji: rozpowszechnianie – ADV, prośba – REQ i dane – DATA. Komunikat rozpowszechniania dystrybuuje informacje, komunikat prośby zgłasza wniosek transmisji danych, a komunikat dane zawiera wnioskowane dane. Protokół zaczyna działać kiedy węzeł wejdzie w posiadanie nowych danych i chce je przekazać. Węzeł taki rozsyła do wszystkich swoich sąsiadów wiadomość ADV zawierającą informację o danych do przekazania. Jeśli węzeł-sąsiad jest zainteresowany danymi wysyła wiadomość REQ a później węzeł transmituje dane – DATA. Następnie węzeł-sąsiad powtarza cały ten proces dla swoich sąsiadów aż każdy zainteresowany danymi węzeł otrzyma informacje. Działanie protokołu SPIN zostało przedstawione na rys.3.3.
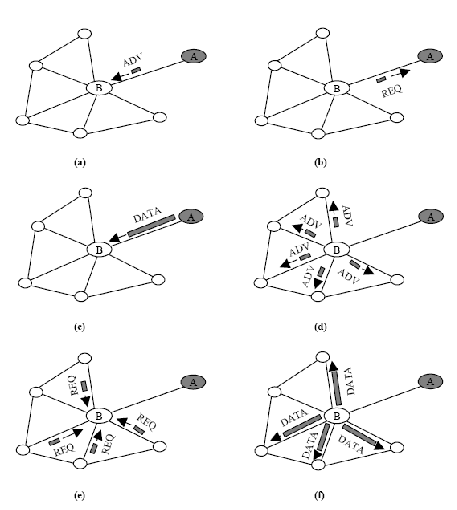
Rysunek 3.6 Protokół SPIN. Węzeł A rozgłasza zawartość swoich informacji do węzła B (a). Węzeł B opowiada wysyłając chęć otrzymania informacji od węzła B(b). Po otrzymaniu informacji (c), węzeł B reklamuje je wśród swoich sąsiadów (d), a kto odpowie prośbą o dane to je otrzyma(e,f).
Protokół SPIN nie jest pozbawiony wad. Jego największą wadą jest wytwarzanie ogromnej liczby wiadomości w przypadku gdy zmierzone dane przez węzeł są wymagane przez wszystkie inne węzły w sieci.
Protokół wykorzystuje ciągły model raportowania danych (ang. time-driven) zamiast zdarzeniowego, co skutkuje przesyłaniem komunikatów rozpowszechniania (ADV) nawet w przypadku gdy nie ma nowych danych w sieci. Innym problemem protokołu SPIN jest fakt, że w przypadku, gdy pewne węzły pomiędzy węzłem źródłowym a nadrzędnym nie poproszą o dane to one nigdy nie dotrą do węzła nadrzędnego. W praktyce protokół SPIN działa tylko jeśli sieć jest mała.
Protokół Directed Diffusion
Protokół Directed Diffusion [11] jest prawdopodobnie najbardziej znanym protokołem rutingu w bezprzewodowych sieciach sensorowych, a wiele innych protokołów bazuje na nim. Protokół zalicza się do protokołów inicjowanych celem, który używa płaskiej struktury sieci o rutingu reaktywnym (ang. destination initiated, flat, reactive). Działa on w sposób efektywny pod względem energetycznym i jest skalowalny. Dodatkowo jest zorientowany na dane w takim sensie, że wszystkie generowane dane przez węzły sensorowe są opisane parą atrybut-wartość. Pozwala to na przeprowadzanie agregacji danych, a przez to zapewnienie efektywnego energetycznie ich dostarczania. W odróżnieniu do tradycjonalnego rutingu opierającego się na adresach węzłów (ang. AC – adress centric) nie ingeruje w treść pakietów. Directed Diffusion jest rutingiem danych (ang. DC - data-centric), w którym zapytanie jest kierowane w określony region sieci a nie w jej całość. Dzięki takiemu rozwiązaniu może używać funkcji agregujących danych i eliminować redundancję.
Protokół składa się z kilku elementów: zapytania, informacji bądź zdarzenia opisanego za pomocą pary atrybut-wartość, gradientu – „drogowskazu” wskazujący skąd przyszło zapytanie oraz algorytmu wyboru ścieżki wg gradientów (ang. reinforcement). Wiadomość zapytania określa dane jakie użytkownik chce uzyskać. Typowo w sieci sensorowej odpowiedź (dane) to informacje zmierzone lub przetworzone przez węzeł podczas badania jakiegoś zjawiska.
Podczas procesu rozprowadzania zapytania w każdym węźle sieci sensorowej jest tworzony gradient, który określa kierunek ku węzłowi z którego przyszło zapytanie. Następnie przeprowadzany jest proces organizacji sieci wraz ze ustawieniem wielu ścieżek od węzła źródłowego do węzła docelowego. Aby nie wykorzystywać nadmiernie sieci i nie wprowadzać narzut algorytm wybiera jedną scieżkę (ewentualnie kilka) i dane są transmitowane. Cały proces pokazany jest na rys.3.4 i oparty jest na algorytmie reinforcement.
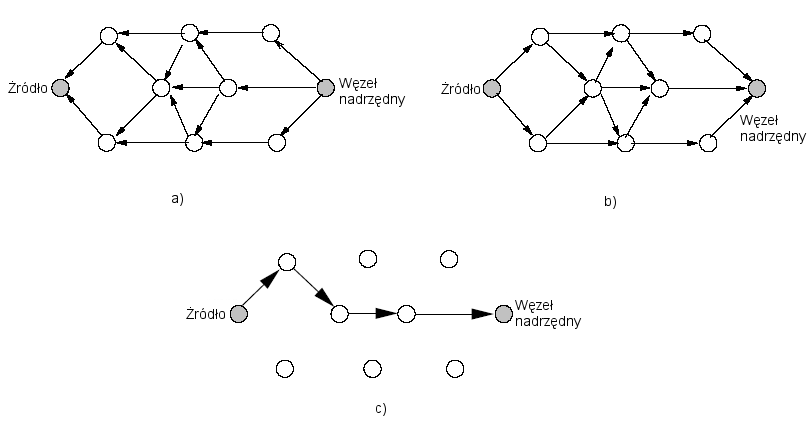
Rysunek 3.7 Dzialanie protokołu Directed Diffusion: a) propagacja zapytania b) zestawienie gradientów c) wysyłanie danych zgodnie z algorytmem reinforcement.
W sieci sensorowej węzły wykonują pomiary i zbierają informację o różnych zjawiskach, zmianach stanów czy występowaniu określonych obiektów na danym terenie. Węzeł pytający generuje natomiast zapytanie. Może ono być dystrybuowane w sieć na różne sposoby: poprzez rozproszenie do wszystkich węzłów, na podstawie położenia geograficznego węzłów (filtracja rozgłoszenia na podstawie współrzędnych) czy inną inteligentną drogą zależącą od aplikacji. Zapytanie określa jakie zadanie ma być wykonane przez sieć rys. 3.5.
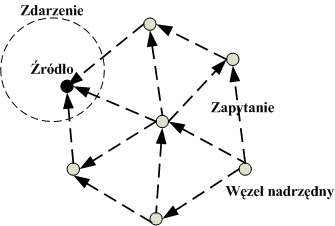
Rysunek 3.8 Zapytanie
Przykładowe zapytanie może wyglądać następująco: co 20 ms przez następne 20 sekund przesyłaj mi pozycje każdego pojazdu kołowego, które jest w regionie [-100, 100, 200, 400] obszaru sieci sensorowej – rys.3.6. Struktura takiego zapytania może wyglądać następująco:

Rysunek 3.9 Przykładowe zapytanie.
Gdy węzeł sieci sensorowej otrzymuje zapytanie sprawdza on jego zawartość i określa czy posiada wymagane dane albo jest w stanie wykonać zadanie z zapytania. Jeśli nie, przesyła zapytanie zgodnie z regułą rozpraszania. W przypadku odwrotnym węzeł przetwarza zapytanie wykorzystuje pamięć podręczną specjalnie przygotowaną dla zapytań (ang. interest cache). Węzeł robi wpis do tej pamięci sprawdzając czy nie ma w niej już podobnego wpisu. W przypadku jego stwierdzenia oba wpisy zostaną zagregowane, a przez to sieć będzie działać bardziej efektywnie.
Podczas przetwarzania zapytania przez węzły w każdym z nich są ustawiane gradienty, aby dane które spełniają zapytanie, mogły być przesyłane do węzła pytającego (ang. sink). Każdy sensor, który otrzyma zapytanie ustawia gradient w stronę węzła, z którego odebrał zapytanie. Przykładowo gradient jest ustawiany od węzła A do węzła B. W taki przypadku składa się on z dwóch wartość <prędkości transmisji – jest to odwrotność pola Interval z zapytania, kierunek – łącze do węzła B>. Proces ten jest kontynuowany do momentu aż gradienty zostaną ustawione na wszystkich węzłach od źródłowych do węzła pytającego – rys 3.7.
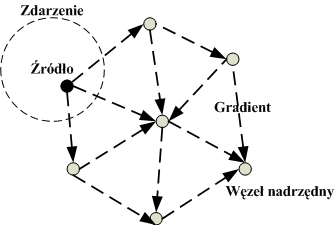
Rysunek 3.7. Ustawienie gradientów.
Jeśli węzeł stwierdzi, że zawiera informacje spełniające zapytanie generuje je w stronę węzła pytającego (ang.sink) wykorzystując w tym celu wartości gradientów do sąsiadów. Odpowiedź na przykład wcześniejszego zapytania może wyglądać jak na rys. 3.8.

Rysunek 3.8. Odpowiedź na zapytanie z rys. 3.6.
Węzeł pośredniczący w transmisji odbiera wysłane dane i je przetwarza. Na początku sprawdza pamięć podręczną zawierająca wpisy o zapytaniach. Jeśli nie znajdzie wpisu odpowiadającego odebranym danym, dane te są usuwane. Jeśli natomiast jest odpowiedni wpis węzeł sprawdza pamięć podręczną związaną z danymi (ang. data cache), która jest ściśle powiązana z pamięcią podręczną zapytań i zawiera ścieżki/ślady ostatnio widzianych danych. Jeżeli w pamięci podręcznej z danym jest wpis, który odpowiada przetwarzanymi danymi dane te są usuwane. W innym przypadku robiony jest w wpis w pamięci poręcznej danych i dane są przesyłane do sąsiadów gdzie procedura się powtarza. Trzeba zauważyć, że wpisy w pamięci podręcznej danych są jednym z mechanizmów zabezpieczających przed powstawanie pętli w sieci. Ostatecznie dane osiągają węzeł pytający – rys. 3.9.
Rys.3.9. Dane z zapytania dostarczone do węzła pytającego.
Węzeł pytający odbierając pierwsze dane spełniające zapytanie rozpoczyna zestawianie optymalnej ścieżki pomiędzy nim a węzłem źródłowym. Dzieję się tak, gdyż przy pierwszej transmisji danych zostały ustawione tzw. gradienty wstępne i dane przepływają ze zmniejszoną prędkością przez sieć. Ponadto, mogą one docierać do węzła pytającego wieloma ścieżkami. Aby zdecydowanie przyśpieszyć transmisję danych i prędkość ich generowania węzeł pytający przesyła nowe zapytanie ze zwiększonym parametrem prędkości generacji danych, co wymusza także szybszą transmisję.
Reasumując należy rozważyć wady i zalety protokołu. Do głównych zalet Directed Diffusion zaliczyć należy:
agregację danych, która znaczenie zmniejsza zużycie energii;
algorytm wybierający najlepszą możliwą ścieżkę;
małą liczbę retransmisji podczas rozgłaszania zapytania.
Jako główne wady niewątpliwie należy wymienić:
fazę zestawiania gradientów, która jest bardzo kosztowna energetycznie;
duże wymagania pamięciowe wobec węzłów - każdy węzeł przetrzymuje wszystkie zapytania jakie odebrał;
brak zorientowania energetycznego - najlepsza ścieżka od źródła do węzła nadrzędnego może być wykorzystywana nadmiernie.
Protokół Rumor Ruting
Protokół Rumor Ruting [6] wywodzi się z protokołu Directed Diffusion i jest protokołem inicjowanym celem, który używa płaskiej struktury sieci o rutingu hybrydowym (ang. destination initiated, flat, hybrid). Zadaniem protokołu jest przekazywanie poprzez rozpływanie (ang. flooding) zdarzeń, a nie jak to miało miejscie w Directed Difussion zapytań. Główna idea stojąca za tym rozwiązaniem jest taka, że zapytania mogą być rutowane tylko do węzłów, które obserwują zdarzenie zawarte w zapytaniu, a nie do wszystkich węzłów w sieci. Aby przekazywać zdarzenia Rumor Ruting używa pakietów zawierających specjalne pole TTL (ang. time to live) nazywanych agentami. Jeśli węzeł zmierzy pewne zdarzenie dodaje je do swojej tablicy zdarzeń i transmituje agenta z polem TTL. Agent zawiera tabele ze zdarzeniami zaobserwowanymi przez węzeł. Podczas swojej podróży poprzez sieć wszystkie węzły odbierające agenta uaktualniają swoją tablicę zdarzeń. Jeśli agent zaobserwuje inne zdarzenie to uaktualnia swoja tabele zdarzeń i propaguje nowe zdarzenie wraz ze zdarzeniem oryginalnym. W procesie wybierania następnego węzła do którego agent będzie transmitowany agent używa listy węzłów, które już odwiedził. Kiedy przybywa do nowego węzła wybiera sąsiada tego węzła, który nie znajduje się na liście. Dodatkowo w czasie przybycia do nowego węzła dekrementowane jest pole TTL. Jeśli wynosi ono 0 to agent jest niszczony. Podczas wysyłania zapytania przez węzeł nadrzędny (ang. sink) jest ono losowo przesyłane do kolejnych węzłów dopóki nie zostanie znaleziona ścieżka do wymaganego zdarzenia.
Rumor Ruting jest przeznaczony dla sieci z niewielką liczbą zdarzeń, ale dużą liczbą zapytań. W przeciwnym przypadku staje on się nieefektywny energetycznie. Dzieje się tak ze względu na wielkość pakietu agenta, który może stać się bardzo duży z powodu zawartości tablicy zdarzeń i listy odwiedzonych węzłów. Tabela i lista mogą bardzo urosnąć w krótkim czasie. Inna wadą protokołu jest fakt, ze agent zawiera tylko jedną ścieżkę do zdarzenia i w przypadku wielu zapytań o to zdarzenie węzły wzdłuż ścieżki mogą bardzo szybko wyczerpać swoje zasoby energetyczne.
Protokół MCFA
Protokół MCFA (ang. Minimum Cost Forwarding Algorithm) [10] zakłada, ze kierunek rutingu jest zawsze znany. Klasyfikując jego cechy można powiedzieć, że jest on inicjowanych źródłem, używa płaskiej struktury sieci, a ruting działa w sposób proaktywny (ang. source initiated, flat, proactive). Węzły sieciowe nie posiadają specjalnych identyfikatorów (ang. ID) i zamiast zarządzać tablicą rutingu obliczają najmniejszy koszt od nich do węzła nadrzędnego. Węzeł nadrzędny ustawia swój koszt minimalny na zero podczas gdy wszystkie inne węzły w sieci ustawiają swój koszt początkowy na nieskończoność. Następnie węzeł nadrzędny rozpowszechnia informacje ze swoim kosztem ścieżki. Węzeł obierający informacje uaktualnia koszt ścieżki do węzła nadrzędnego jeśli koszt zawarty w informacji plus koszt ścieżki jest mniejszy od aktualnego ustawionego kosztu. Kosztem ścieżki może być liczba węzłów, opóźnienie bądź inna metryka. Jeśli nowy koszt jest mniejszy to węzeł rozsyła informacje, a w przeciwnym razie ją niszczy. W ten sposób jest ustawiany minimalny koszt w każdym węźle sieci.
Jeśli węzeł zamierza wysłać wiadomość to rozgłasza ją do wszystkich swoich sąsiadów. Węzeł, który odbierze wiadomość, sprawdza czy jest on na najmniej kosztownej ścieżce do węzła nadrzędnego. Jeśli tak to rozgłasza tą wiadomość do wszystkich swoich węzłów-sąsiadów. Takie działanie jest powtarzane, aż wiadomość nie osiągnie węzła nadrzędnego.
Dużym problemem algorytmu MCFA jest fakt, że wzdłuż określonej ścieżki może wystąpić nadmierne wykorzystanie energii jeśli metryka kosztu nie jest okresowo uaktualniana. Inny problem algorytmu może wystąpić jeśli jako koszt zostanie określona liczba węzłów lub jeśli węzły zostaną jednolicie rozmieszczone i zużycie energii będzie oznaczało koszt. Wtedy wiele węzłów będzie taktować siebie samego jako węzeł z minimalnym kosztem ścieżki i protokół stanie się protokołem flooding.
Protokół Energy Aware Routing
Protokół Energy Aware Routing [19] jest inicjowany celem, używa płaskiej struktury sieci z rutingiem proaktywnym (ang. destination initiated, flat, proactive). Ponadto jest bardzo podobny do zaprezentowanego powyżej protokołu Directed Diffusion, choć każdy węzeł zarządza wieloma ścieżkami zamiast jednej. Ścieżki są zestawiane pomiędzy źródłem a celem i każdej ścieżce przypisywane jest prawdopodobieństwo, które zależy od metryki energetycznej. Za każdym razem jak są przesyłane dane jedna ze ścieżek jest losowo wybierana zależnie od prawdopodobieństwa.
Protokół składa się ze trzech faz: zestawienia, przesyłana danych i zarządzania ścieżkami. Podczas fazy zestawiana za pomocą protokołu lokalizowanego rozpływania (ang. localized flooding) budowane są tablice rutingu dla każdego węzła. W czasie drugiej fazy dane są przesyłane ze źródła do celu. Ostatnia faza to faza zarządzania ścieżkami podczas której używany jest protokół lokalizowanego rozpływania (ang. localized flooding).
Główną wadą tego protokołu są założenia jego działania. Założenia, że wszystkie węzły są zlokalizowane i zapytania są przesyłane tylko do węzłów, które są bliżej źródła, a później dalej od celu w kierunku źródła. Inną wadą jest wymóg posiadania przez węzły dwóch nadajników. Zaznaczyć należy, że również faza zestawiania jest bardzo skomplikowana ze względu na wymóg adresowania węzłów biorąc pod uwagę ich lokalizacje i typ węzłów.
Protokół Random Walks
Protokół Random Walks [5] to protokół routingu wielościeżkowego, który implementuje sterowanie obciążeniem ruchu. Protokół jest inicjowany celem, używa płaskiej struktury sieci i przeprowadza ruting reaktywny (ang. destination initialized, flat, reactive). Jak założyli twórcy jest on przeznaczony specjalnie dla dużych sieci ze statycznymi węzłami. Każdy węzeł w sieci ma unikalny identyfikator ID, choć topologia sieci jest mało praktyczna. Sieć jest tak zorganizowana, że wszystkie węzły w sieci są lokalizowane w punktach przecięcia siatki na płaszczyźnie. Do znajdowania optymalnej ścieżki wykorzystywana jest asynchroniczna wersja algorytmu Bellmana-Forda, który jest uogólnieniem algorytmu Dijkstry. Algorytm Dijksty jest używany do obliczania pojedynczej i najkrótszej ścieżki ze źródła w grafie ważonym, w którym wagi krawędzi mają wartości dodatnie. Natomiast algorytm Belmana-Forda działa prawie tak samo, choć może dokonywać wyliczeń na wagach ujemnych. Węzły pośrednie działające po protokołem wybierają zawsze sąsiada, który jest najbliżej celu zgodnie z pewnym prawdopodobieństwem. Kierowanie obciążeniem ruchu jest wykonywane poprzez sterowanie tym prawdopodobieństwem.
Głównym problemem protokołu jest wymóg odpowiednio ukształtowanej topologii sieci, co jest bardzo niepraktyczne.
Protokół MECN
Protokół MECN (ang. Minimum Energy Communication Network) [14], [7] jest protokołem rutingu bazującym na lokalizacji, który stara się osiągnąć efektywność energetyczna poprzez minimalizacje poboru mocy podczas transmisji. Klasyfikowany jest jako protokół inicjowany źródłem, który używa płaskiej struktury sieci o rutingu reaktywnym(ang. source initiated, flat, reactive). W czasie działania protokółu dla każdego węzła tworzony jest region transmisyjny. Składa się on z węzłów przez które wybrany węzeł może transmitować dane w kierunku węzła nadrzędnego w sposób oszczędny energetycznie. Moc transmisyjna potrzebna do osiągnięcia węzła w odległości d w każdym systemie bezprzewodowym radiowym jest proporcjonalna do zależności dα , gdzie: α jest współczynnikiem straty przyjmowanym w przedziale ( 2 ≤ α ≤ 4 ). Biorąc ten fakt po uwagę protokół wybiera ścieżkę ze źródła do węzła nadrzędnego, która posiada więcej węzłów przejściowych z mniejszym dystansem transmisyjnym. Dodatkowo rozważana jest różna wielkość zasobów mocy transmisyjnej w każdym węźle. Protokół zakłada także, ze każdy węzeł w sieci jest w zasięgu transmisyjnym wszystkich węzłów w sieci. Węzły w sieci są lokalizowane za pomocą odbiorników GPS, w które muszą być wyposażone.
Wymaganie posiadania odbiornika GPS zużywającego znaczne ilości energii w każdym węźle oraz potrzeba bycia w dystansie transmisyjnym wszystkich węzłów powoduje, że protokół jest mało praktyczny w sieciach sensorowych.
komentarze
Copyright © 2008-2010 EPrace oraz autorzy prac.